

Xiaomiは2月12日、同社初となるロボット向け大規模モデル「Xiaomi-Robotics-0」を発表しました。スマートフォンやスマートホーム機器、EV分野で存在感を高めてきた同社ですが、今後はロボティクス分野にも本格参入する構えです。
Robotics-0は、視覚・言語・行動を統合するVLAモデルで、パラメータ数は47億。オープンソースとして公開され、シミュレーション環境と実機の両方で最先端水準の成果を上げているとしています。
視覚から行動までを一貫処理する設計

ロボットが現実世界で動作するには、「認識」「判断」「実行」という一連の流れを途切れなくこなす必要があります。周囲を見て状況を理解し、与えられた指示を解釈し、適切な動作を選び、滑らかに実行するという閉じたループを構築しなければなりません。
Xiaomiはこれを「物理知能」と呼び、Robotics-0は広範な理解力と精密な運動制御の両立を目指して設計されたと説明しています。
2つの中核モジュールで構成
Robotics-0は、Mixture-of-Transformersアーキテクチャを採用し、役割の異なる2つの主要コンポーネントで構成されています。
頭脳を担うVisual Language Model
1つ目はVisual Language Modelです。これは人間の指示を理解し、カメラから取得した高解像度の映像情報と結び付けて解釈する役割を担います。

「タオルをたたんでください」といった曖昧な指示にも対応できるよう設計されており、物体検出や視覚質問応答、論理的推論などを処理します。ロボットにとっての思考中枢といえる存在です。
滑らかな動きを生むAction Expert
もう1つはAction Expertと呼ばれるモジュールで、マルチレイヤーのDiffusion Transformerを基盤としています。
従来のように単一の動作を逐次出力するのではなく、「Action Chunk」と呼ばれる一連の動作シーケンスを生成します。これにより、動作の精度と連続性を高め、ぎこちない動きを抑えることが可能になるとされています。
段階的な学習プロセスと遅延対策
学習は段階的に行われます。まず、Visual Language Modelに対して「Action Proposal」機構を用い、画像を解釈しながら想定される動作分布を予測させます。これにより、視覚情報と行動の内部表現を整合させます。
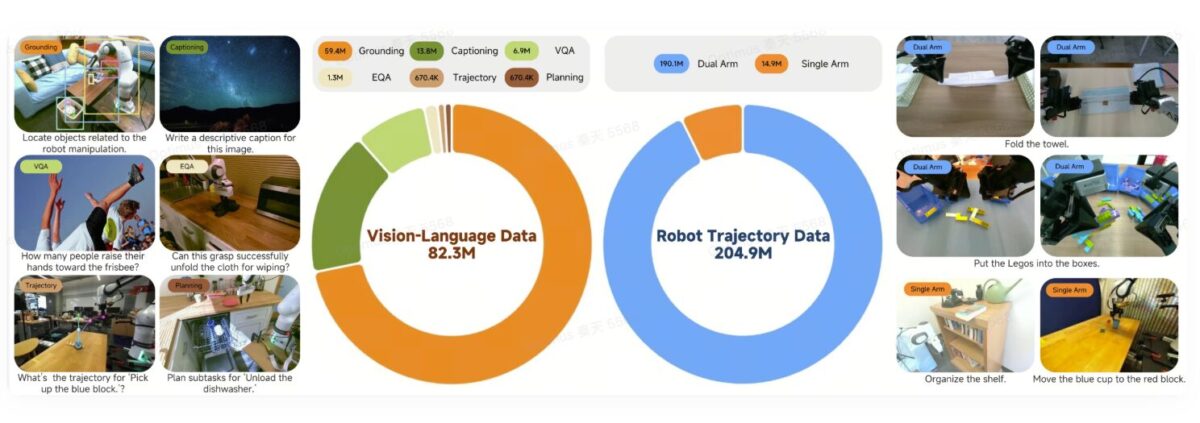
その後、Visual Language Modelを固定し、Diffusion Transformer側を個別に訓練。ノイズから正確な動作シーケンスを生成できるようにします。
また、ロボット分野で課題となる推論遅延にも対策を講じています。モデルの計算とロボットの動作を切り離す非同期推論を導入することで、思考時間が長くなっても動きが途切れないよう設計されています。
さらに、直前の動作を再入力する「Clean Action Prefix」技術を採用し、時間経過によるブレや振動を抑制。Λ型のアテンションマスクによって、過去情報に依存しすぎず、現在の視覚入力を重視する仕組みも組み込まれています。これにより、急な環境変化にも素早く対応できるといいます。
ベンチマークと実機テストで高評価
ベンチマークテストでは、LIBEROやCALVIN、SimplerEnvといったシミュレーション環境で最先端水準の結果を記録し、約30の他モデルを上回ったとしています。
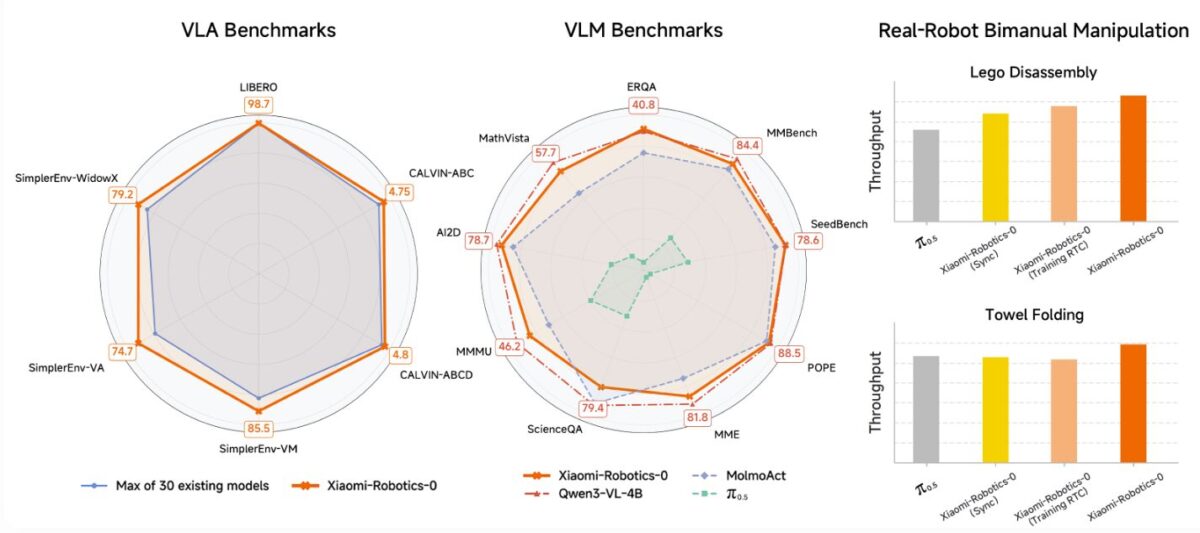
さらに、デュアルアームロボットに実装した実機検証も実施。タオルを折りたたむ作業やブロックの分解といった長時間タスクにおいて、安定した手と目の協調動作を実現したと報告されています。硬い物体だけでなく、柔軟な対象物も扱える点が強調されています。
従来のVLAモデルでは、動作学習を進めると視覚や言語の理解力が低下する傾向がありましたが、Robotics-0はマルチモーダル理解能力を維持している点も特徴とされています。
スマートフォンメーカーとして知られるXiaomiですが、今回の発表は同社がAIとロボット技術を融合させた次世代領域へ踏み出したことを示す動きといえます。今後、研究成果がどのような製品やサービスに結び付いていくのか、注目が集まりそうです。


